

BLOCKADE Ebook Scanner Setup Guide
Here's a step-by-step guide to get the “Blocking Lustful Overzealous Content, Keeping Away Depravity and Extremism from children” script running on a Windows PC that does not have Python installed.





This guide will walk you through installing Python, setting up the required dependencies, and running the script. The script uses several Python libraries, so we’ll ensure all dependencies are installed properly.
To start, you will need to bring your own 𝕏ai api access. Stat by setting access up following the instrictions below, and input your API🔑 in the script (can be edited with a normal text editor, although I prefer the more versatile Notepad++)
You will need this to allow you to generate an api key to call Grok 𝕏ai from within an application.
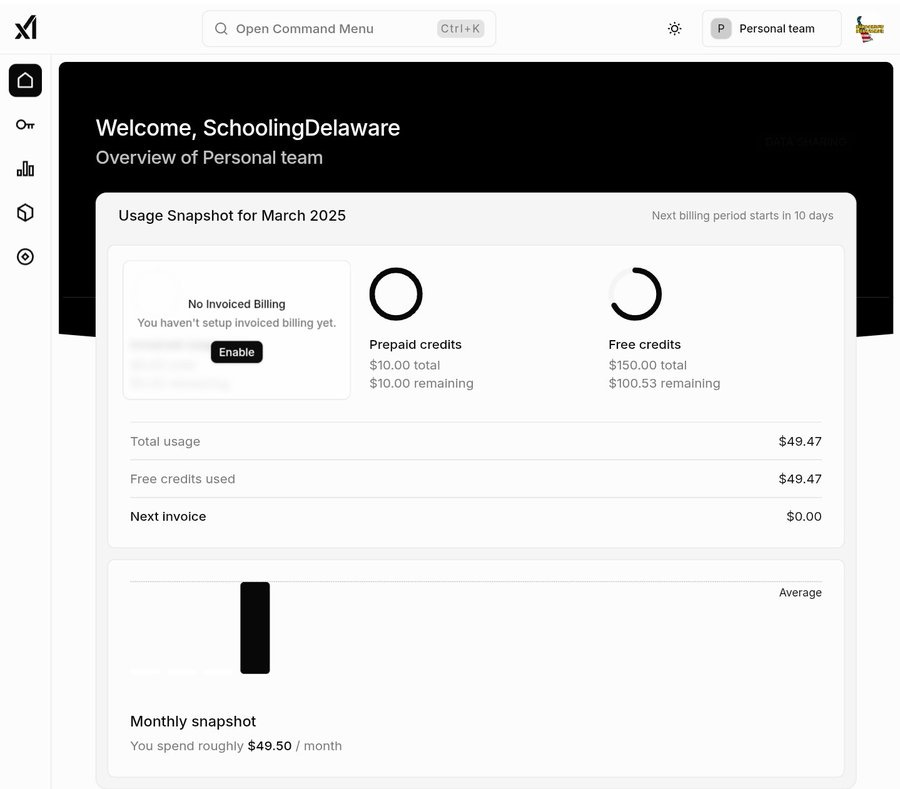
I received $150 in monthly bonus credits for signing up during early testing with a one time payment of $10. (Could possibly receive the bonus with less) I have scanned thousands of pages of images & text, and have only today broken past $40. With some more refinement of the code, I am certain even that can be reduced.
Set up api access here:
Step-by-Step Guide to Running the Script on a Windows PC
Step 1: Download and Install Python
Visit the Python Website:
Open a web browser and go to the official Python website: https://www.python.org/downloads/.
The website will automatically suggest the latest stable version of Python for Windows (as of March 25, 2025, this might be Python 3.12 or later).
Download the Installer:
Click the "Download Python 3.x.x" button to download the installer (e.g., python-3.12.3-amd64.exe for 64-bit Windows).
If you’re unsure whether your PC is 64-bit or 32-bit, you can check by going to Settings > System > About in Windows and looking under "Device specifications" for "System type."
Run the Installer:
Double-click the downloaded .exe file to run the installer.
Important: Check the box that says "Add Python 3.x to PATH" at the bottom of the installer window. This ensures Python and its package manager (pip) are accessible from the command line.
Click "Install Now" and follow the prompts to complete the installation.
Verify Python Installation:
(I prefer to use a program called “powershell" which comes pre-installed with all recent versions of Windows, but is not neccessary. Just search “powershell", updating if prompted, and then enter the commands outlined below. Use powershell anytime Command Prompt is referenced)
Open the Command Prompt (press Win + R, type cmd, and press Enter).
Type the following command and press Enter:
python --versionYou should see the Python version (e.g., Python 3.12.3). If you see an error, ensure the "Add Python to PATH" option was selected during installation, or reinstall Python with this option enabled.
Also verify pip (Python’s package manager) by running:
pip --versionYou should see the pip version (e.g., pip 24.0 from ...). If pip is not found, you may need to reinstall Python.
Step 2: Create a Working Directory for the Script
Create a Folder:
(Again, I prefer creating a folder in the root of the C:\ drive)
On your desktop or a preferred location, create a new folder (e.g., pdfscanner).
Right-click on your desktop, select New > Folder, and name it PDFScanner. (Or in explorer, select the C: drive and create the new folder there)
Save the Script:
Copy the script & logo image into that folder.
pdfscanGUI.py robot_input.png
Step 3: Install Required Dependencies
The script uses several Python libraries that need to be installed. We’ll use pip to install them.
Open Command Prompt:
Press Win + R, type cmd, and press Enter to open the Command Prompt.
Navigate to the Script Directory:
Change the directory to your PDFScanner folder. For example, if the folder is on your desktop:
cd %userprofile%\Desktop\pdfscanner
OR
cd C:\pdfscannerPress Enter.
Install Dependencies:
Run the following commands one by one to install each required library. These are the dependencies used in the script:
pip install tkinter
pip install PyMuPDF
pip install Pillow
pip install requests
pip install ebooklib
pip install beautifulsoup4
pip install reportlab
pip install pydanticNotes:
tkinter is typically included with Python, but the command ensures it’s available.
PyMuPDF is the library for handling PDFs (imported as fitz).
Pillow is for image processing (imported as PIL).
requests is for making API calls.
ebooklib is for handling EPUB files.
beautifulsoup4 (imported as bs4) is for parsing HTML in EPUB files.
reportlab is for generating PDFs.
pydantic is for data validation.
If any installation fails, ensure your pip is up to date by running:
pip install --upgrade pipThen retry the failed command.
Verify Installations:
You can check if the libraries are installed by running:
pip listLook for PyMuPDF, Pillow, requests, ebooklib, beautifulsoup4, reportlab, and pydantic in the list.
Step 4: Prepare a Test File
Obtain a PDF or EPUB File:
A few sources are listed below:
The script processes PDF or EPUB files. For testing, you’ll need a sample file.
PDF is preferred when available because some epubs are not structured / packaged properly & may cause issues.
Optional: Prepare a Cover Image:
The script allows you to specify a cover image for the book. If you have a cover image (e.g., cover.jpg) you may select it from within the application. If not, the script will use the first page of the PDF or a default gray image for EPUBs.
Step 5: Run the Script
Open Command Prompt (if not already open):
Ensure you’re still in the PDFScanner directory in the Command Prompt:
cd %userprofile%\Desktop\pdfscannerC:\pdfscannerRun the Script:
Execute the script by running:
python pdfscanGUI.pyA graphical user interface (GUI) window titled "BLOCKADE PDF/EPUB Content Scanner" should appear.
Use the GUI:
Select File: Click the "Select File" button and browse to your ebook (bookX.pdf or bookX.epub).
Enter Book Details:
In the "Book Title" field, enter the title (e.g., “Lucky").
In the "Author" field, enter the author (e.g., "Alice Sebold").
Optional: Select Cover Image: Click "Select Cover Image" and choose your cover image if you have one, otherwise leave blank.
Set Output Options:
Choose "Pack to PDF" (default) to save the output as a PDF file.
Optionally check "Include Report" to generate a content analysis report.
Leave "Challenge Report" unchecked for standard scanning.
Start Scanning: Click the "Scan File" button to begin the process.
The script will scan the file for offensive content, display progress in the GUI, and save the output in the PDFScanner folder (e.g., as Lucky_flagged_content.pdf).
View the Output:
Once the scan is complete, a message box will pop up with information such as elapsed time & the location of the output file.
Open the output PDF (e.g., Pride_and_Prejudice_flagged_content.pdf) to view the index page with the offensive content tally and any flagged pages.
Step 6: Troubleshooting
Error: "python is not recognized":
Ensure Python was added to your PATH during installation. Reinstall Python and check the "Add Python 3.x to PATH" box.
Error: Module Not Found:
If you see an error like ModuleNotFoundError: No module named 'PyMuPDF', ensure you installed the dependency correctly. Rerun the corresponding pip install command (e.g., pip install PyMuPDF).
API Key Issues:
The script uses an API key (XAI_API_KEY) to make requests to https://api.x.ai/v1. If the key is invalid or expired, the script will fail to scan content. You’ll need a valid API key from xAI to use this feature. If you don’t have one, you may need to modify the script to bypass API calls or use a different content analysis method.
GUI Not Appearing:
Ensure your Windows PC supports graphical applications. If the GUI doesn’t appear, there might be an issue with tkinter. Reinstall Python and ensure tkinter is included (it’s part of the standard Python installation on Windows).
File Not Found (robot_input.png):
If the script can’t find robot_input.png, it will skip rendering the robot image. Ensure the file exists in the pdfscanner folder.
Step 7: Optional - Create a Batch File for Easy Running
To make running the script easier in the future:
Open Notepad and create a new file with the following content:
@echo off
cd C:\pdfscanner
python pdf_scanner.py
pauseSave the file as run_scanner.bat in the PDFScanner folder (set "Save as type" to "All Files (.)").
Double-click run_scanner.bat to run the script without opening the Command Prompt manually.
Summary of Dependencies
Python: Installed in Step 1.
Libraries:
tkinter (for the GUI)
PyMuPDF (for PDF processing)
Pillow (for image processing)
requests (for API calls)
ebooklib (for EPUB processing)
beautifulsoup4 (for HTML parsing in EPUBs)
reportlab (for PDF generation)
pydantic (for data validation)
Additional Notes
Internet Connection: The script makes API calls to https://api.x.ai/v1, so an internet connection is required unless you modify the script to work offline.
Windows Compatibility: This guide is tailored for Windows 10 or 11. If you’re using an older version of Windows, some steps (e.g., GUI support) might require additional configuration.
Performance: Scanning large PDF/EPUB files may take time, especially if the API calls are slow. Ensure your PC has sufficient memory and processing power.
Let me know if you encounter any issues while setting this up!
My goal is to iron out all the bugs, tweak some QOL settings, and package thos into a self contained portable app anyone can download & use.
Message me with any feedback at @schoolingdel on 𝕏 or here on substack Gaetano. https://x.com/SchoolingDel/status/1901285566131396773
Happy hunting!